
나랑 now
[혼공머신] 2주차_회귀 알고리즘과 모델 규제 본문
반응형
| # | 진도 | 기본 미션 | 선택 미션 |
| 1주차 (1/2 ~ 1/7) |
Chapter 01 ~ 02 | 코랩 실습 화면 캡처하기 | Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기 |
| 2주차 (1/8 ~ 1/14) |
Chapter 03 | Ch.03(03-1) 2번 문제 출력 그래프 인증하기 | 모델 파라미터에 대해 설명하기 |
| 3주차 (1/15 ~ 1/21) |
Chapter 04 | Ch.04(04-1) 2번 문제 풀고, 풀이 과정 설명하기 | Ch.04(04-2) 과대적합/과소적합 손코딩 코랩 화면 캡처하기 |
| 4주차 (1/22 ~ 1/28) |
Chapter 05 | 교차 검증을 그림으로 설명하기 | Ch.05(05-3) 앙상블 모델 손코딩 코랩 화면 인증하기 |
| 5주차 (1/29 ~ 2/4) |
Chapter 06 | k-평균 알고리즘 작동 방식 설명하기 | Ch.06(06-3) 확인 문제 풀고, 풀이 과정 정리하기 |
| 6주차 (2/5 ~ 2/12) |
Chapter 07 | Ch.07(07-1) 확인 문제 풀고, 풀이 과정 정리하기 | Ch.07(07-2) 확인 문제 풀고, 풀이 과정 정리하기 |
- 지도 학습 알고리즘
- 분류(Classification): 여러 개의 클래스 중 하나를 구별해 내는 문제
- 회귀(Regression): 임의의 어떤 숫자를 예측하는 문제
- k-최근접 이웃 회귀
- k-최근접 알고리즘:
1. 예측하려는 샘플에 가장 가까운 샘플 k개를 선택
2. 샘플들의 클래스를 확인하여 다수 클래스를 새로운 샘플의 클래스로 예측 - k-최근접 회귀 알고리즘:
1. 예측하려는 샘플에 가장 가까운 샘플 k개를 선택
2. 이웃 샘플의 수치를 사용해 평균치를 통해 새로운 샘플의 타깃을 예측
ex) 이웃 샘플의 타깃값 100, 80, 60: 샘플의 타깃값 (100+80+60)/3 = 80
k-최근접 회귀는 분산형 변수보다는 연속적인 데이터에 적합
모델 복잡도 증가하기 위한 방법: k개수를 줄임(훈련 세트에 있는 국지적인 패턴에 민감해짐)
- k-최근접 알고리즘:
- 결정계수(R²)
- 회귀 모델에서는 예측하는 값이나 타깃이 모두 임의의 수치이므로 정확한 숫자를 맞힌다는 것은 불가능
- 회귀 모델에서의 평가값은 결정계수coeffiecient of determination 또는 R²으로 표현
- R² = 1 - {(타깃-예측)²의 합}/{(타깃-평균)²의 합}
- 0에서 1에 가까울수록 모델의 성능이 좋음
- 결정계수는 정확도처럼 직감적으로 얼마나 좋은지 이해하기 어려움
- 과대적합 vs 과소적합
- 일반적으로 모델을 훈련 세트에 훈련을 하면 훈련 세트에 잘 맞는 모델이 만들어지며, 해당 모델을 훈련 세트와 테스트 세트에서 각각 평가하면 보통 훈련 세트의 점수가 더 높게 나옴
- 과대적합overfitting: 훈련 세트에 비해 테스트 세트에서 점수가 너무 낮은 경우
훈련 세트에만 맞는 모델이라 테스트 세트와 새로운 샘플에 대해 잘못된 예측을 하게 됨 - 과소적합underfitting: 훈련 세트보다 테스트 세트의 점수가 높거나 두 점수 모두 너무 낮은 경우
모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않은 경우
또한 훈련 세트와 테스트 세트의 크기가 매우 작기 때문에 발생하기도 함


- 선형 회귀(linear regression)
- k-최근접 이웃 알고리즘은 타겟에게 근접해있는 샘플들의 값을 참고하기 때문에 학습 데이터 세트의 범위를 벗어나면 엉뚱한 값을 예측할 수 있음
- 선형 회귀(linear regression): 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘
- 직선의 방정식 y = ax + b
하나의 직선을 그리기 위해선 기울기 a와 y절편이 있어야 함
LinearRegression은 coef_ 속성에 기울기 a를, intercep_ 속성에 절편 b를 저장- coef_와 intercep_를 머신러닝이 찾은 값이라는 의미로 모델 파라미터(model parameter)라고 함.
머신러닝 알고리즘의 훈련 과정은 최적의 모델 파라미터를 찾는 것- 모델 기반 학습: 모델 파라미터가 있는 경우
사례 기반 학습: 모델 파라미터가 없이 훈련 세트를 저장하는 것이 훈련의 전부인 경우
- 모델 기반 학습: 모델 파라미터가 있는 경우
- coef_와 intercep_를 머신러닝이 찾은 값이라는 의미로 모델 파라미터(model parameter)라고 함.

- 다항 회귀(polynomial regression)
- 비선형 데이터를 학습하기 위한 다향식을 사용한 선형 회귀
- 각 특성의 거듭제곱을 새로운 특성으로 추가하여, 확장된 특성을 포함한 데이터셋을 선형 모델에 훈련

- 다중 회귀(multiple regression)
- 여러 개의 특성을 사용한 선형 회귀
- 선형 회귀는 특성이 많을수록 더 좋은 결과를 냄
- 특성 공학(feature engineering)
- 기존의 특성을 사용하여 새로운 특성을 뽑아내는 작업
- 샘플 개수보다 특성이 더 많다면 모델이 과대적합되어 테스트 세트 혹은 새로운 샘플을 예측하지 못하는 경우가 발생할 수 있음
- 규제(regularization)
- 머신러닝 모델이 훈련 세트에 과대적합되지 않도록 만드는 것
- 선형 회귀 모델의 경우 특성에 곱해지는 계수(기울기)의 크기를 작게 만듬
- 릿지(ridge)와 라쏘(lasso):
선형 회귀 모델에 규제를 추가한 모델
릿지: 계수를 제곱한 값을 기준으로 규제를 적용
라쏘: 계수의 절대값을 기준으로 규제를 적용- 두 알고리즘 모두 계수의 크기를 줄이지만 라쏘는 아예 0으로 만들 수 있으므로, 일반적으로 릿지가 선호됨


- 하이퍼파라미터(hyperparameter)
- 머신러닝 모델이 학습할 수 없고 사람이 알려줘야 하는 파라미터
- 사이킷런과 같은 머신러닝 라이브러리에서 하이퍼파라미터는 클래스와 메서드의 매개변수로 표현됨
기본 미션
Ch.03(03-1) 2번 문제 출력 그래프 인증하기
# k-최근접 이웃 회귀 객체를 만듭니다
knr = KNeighborsRegressor()
# 5에서 45까지 x 좌표를 만듭니다
x = np.arange(5, 45).reshape(-1, 1)
# n = 1, 5, 10일 때 예측 결과를 그래프로 그립니다
for n in [1, 5, 10]:
# 모델을 훈련합니다
knr.n_neighbors = n
knr.fit(train_input, train_target)
# 지정한 범위 x에 대한 예측을 구합니다
prediction = knr.predict(x)
# 훈련 세트와 예측 결과를 그래프로 그립니다
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()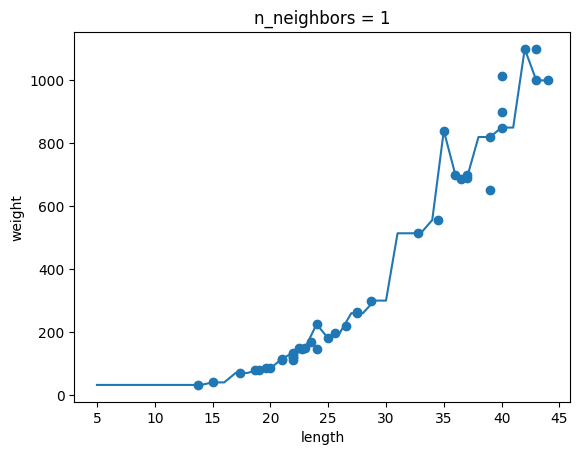


선택 미션
모델 파라미터에 대해 설명하기
머신러닝에서 말하는 모델 파라미터는, 모델을 학습시키는 과정에서 알고리즘이 찾은 값을 의미한다.
선형모델의 경우 직선을 그리기 위한 기울기와 y절편을 선형모델 알고리즘의 파라미터라고 할 수 있는데,
결국 모델을 학습시킨다는 것의 의미는 학습 데이터와 타겟으로 테스트 데이터와 타겟 및 새로운 샘플에 대해 정확하게 예측할 수 있는 최적의 모델 파라미터를 찾는다는 것과 같다.
또한 머신러닝에서는 모델 파라미터 값이 존재하는 알고리즘과 그렇지 못한 알고리즘이 존재하는데, 전자를 모델 기반 학습이라 하며 후자를 사례 기반 학습이라고 부른다.
분량은 짧았지만 본격적인 머신러닝 알고리즘에 대한 분석과 여러 패키지에 대한 기술적인 부분에 익숙하지 않아서 이 부분을 좀 더 찾아봐야겠음.
맷플롭립을 그리는 과정은 매번 즐겁다... 이상한가...
모델 학습에 대한 방법론이나 관련 메소드의 파라미터 값을 살펴보며 추가 학습이 필요!!!
반응형
'혼공학습단 > 혼공머신' 카테고리의 다른 글
| [혼공머신] 6주차_딥러닝을 시작합니다 (0) | 2024.02.16 |
|---|---|
| [혼공머신] 5주차_비지도학습 (0) | 2024.02.05 |
| [혼공머신] 4주차_트리 알고리즘 (0) | 2024.01.29 |
| [혼공머신] 3주차_다양한 분류 알고리즘 (1) | 2024.01.22 |
| [혼공머신] 1주차_나의 첫 머신러닝 & 데이터 다루기 (0) | 2024.01.07 |
'혼공학습단/혼공머신' Related Articles
more



